
Introduction
Edge computing is a relatively new concept that has emerged from the need to process data in real time. Since traditional cloud computing often takes too long to process and analyze data, edge computing was created as an alternative solution.
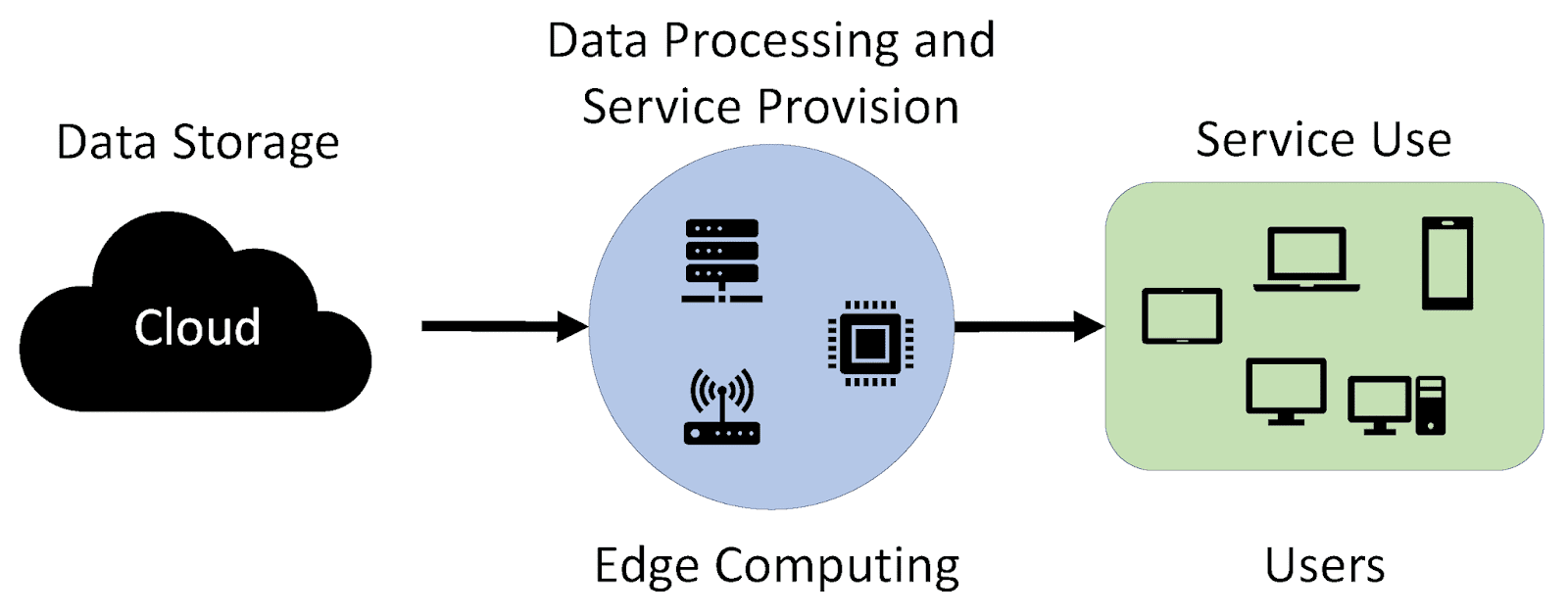
Edge Computing
Edge computing is a new concept that is becoming increasingly popular. Edge computing refers to the processing of data at the edge of a network, rather than in centralized data centers. The term “edge” refers to the physical location where this type of processing takes place–on devices such as smartphones and other mobile devices, sensors and cameras embedded in industrial machinery, vehicles and autonomous drones.
Edge computing has many advantages over traditional centralized cloud-based models:
- It allows real-time analysis of large amounts of information by having access to more sources than would be possible with conventional methods. For example, if you’re driving down a highway and have your phone connected via Bluetooth or WiFi Direct (a wireless protocol used for short range communications), then you can use its sensors or camera(s) as part of an autonomous vehicle system that detects obstacles ahead such as pedestrians crossing against traffic lights or cars slowing down unexpectedly due to mechanical problems
Data Processing
Data processing is the process of converting data into information. It is a subset of data management, and can be done in real time or offline. Data processing can be done by humans, computers or both. In edge computing environments where resources are limited, it’s common for only one person to do all the data processing tasks themselves–but this isn’t always possible because there may not be enough time available for them to get everything done before their next shift ends!
Data processing includes activities such as extracting features from raw sensor readings using artificial intelligence models; aggregating multiple sources into a single view (for example: combining temperature readings from different sensors); filtering out irrelevant events/data points based on certain criteria (elevated temperatures above 70 degrees Fahrenheit); summarizing large amounts of information into smaller chunks so people can easily understand them (such as creating graphs showing historical trends over time)
The three major data types processed by Edge Computing are structured, semi-structured and unstructured data.
Structured data is most commonly found in databases and is often used for decision making purposes. Semi-structured data is the next step up from structured data, and typically comes from sensors. Unstructured data includes text documents, video files and images.
Edge computing can be used to process all three types of data because it’s designed to handle large amounts of information quickly without needing to pass everything through a central server before processing or storing it somewhere else on your network.
Structured data is most commonly found in databases and is often used for decision making purposes.
Structured data is most commonly found in databases and is often used for decision making purposes. This type of data uses a common format, so it’s easy to store and access. Structural information includes things like names, addresses, and phone numbers–or anything else that can be easily stored as a string of characters (text). You can use structured data for any number of tasks including querying for specific information or performing calculations on the fly based on user inputted data.
Example: You might have an online shopping cart that tracks inventory levels by item as well as customer orders; these two pieces would be considered structured because they both use similar formats (numbers) that allow them to easily link together into one cohesive system
Semi-structured data is the next step up from structured data and typically comes from sensors.
Semi-structured data is the next step up from structured data, and typically comes from sensors. It’s a mix of both structured and unstructured information.
Semi-structured data can be found in the cloud or on edge devices themselves and is often used for decision making purposes.
Examples of unstructured data include text documents and video files.
Unstructured data is often used for communication and entertainment, such as text documents and video files. Unstructured data can be challenging to process in a centralized system because it requires extensive processing power and bandwidth resources. However, edge computing systems are well-suited to handle this type of information because they’re designed to work with unstructured content at the edge of the network where it resides.
A variety of data types need to be processed in different ways before being analyzed by an algorithm
- Structured data is the most commonly found type, and it’s usually used for decision making. It’s typically found in databases or spreadsheets.
- Semi-structured data is the next step up from structured data and often comes from sensors (such as those on your phone).
- Unstructured data includes text documents, video files and other media content that can’t be neatly categorized into pre-defined fields–it’s more like a big pile of facts with no clear hierarchy between them all!
Conclusion
Data processing is a complex task, but it’s also one of the most important parts of Edge Computing. The ability to process data at the edge means that our devices can make smarter decisions based on real-time information instead of waiting hours or days for an update from the cloud.
