
Introduction
The cloud is great. It has allowed us to access data from anywhere, on any device. But sometimes it isn’t enough—there are times when we need real-time information and fast speed so that we can make decisions or take action quickly. Edge computing allows us to do just that by delivering data processing and analytic capabilities right where you need them most: at the edge of the network
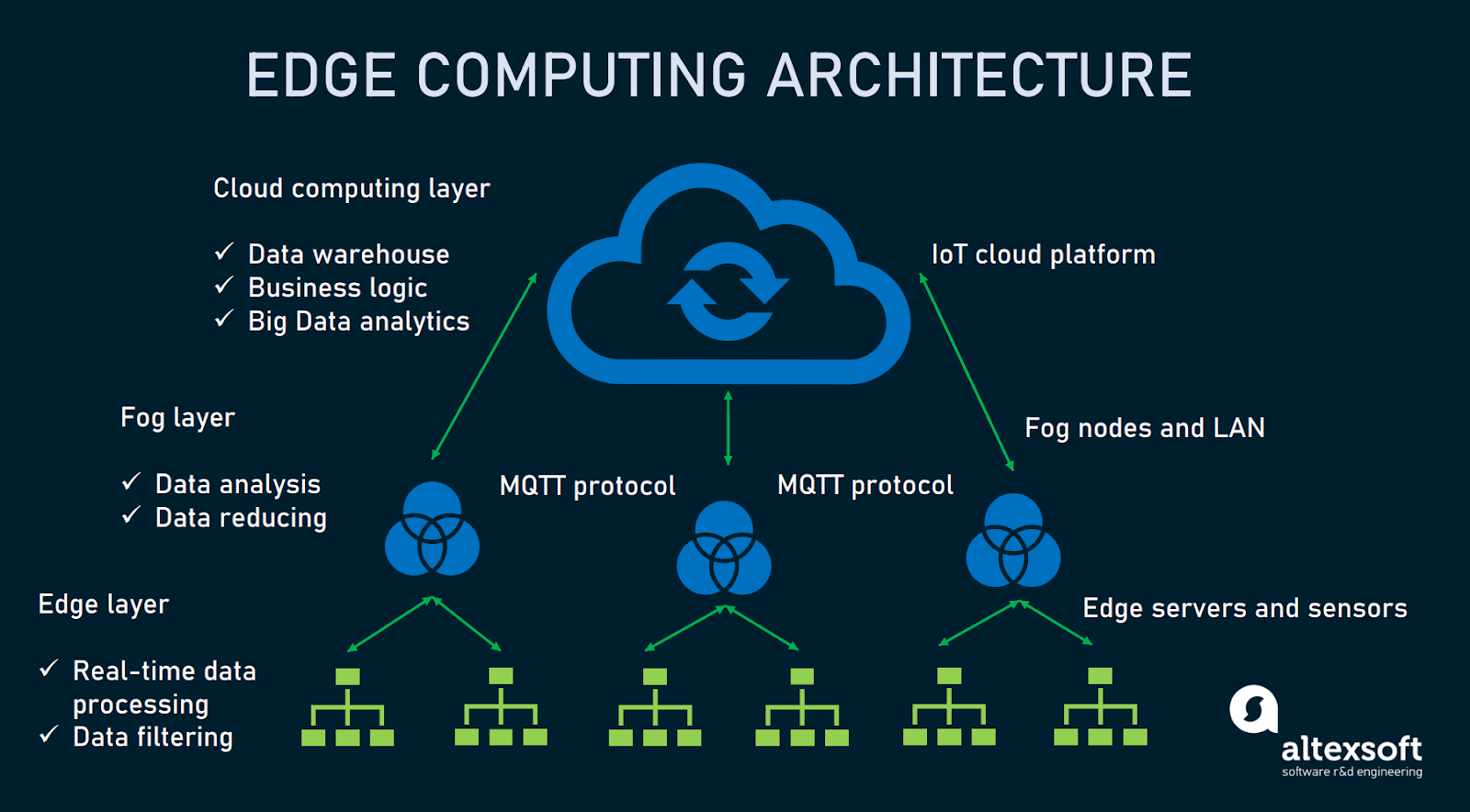
Edge computing is a new way to process and analyze data.
Edge computing is a new way to process and analyze data. It’s different from cloud computing, which involves sending data to the cloud and then analyzing it there. In edge computing, you process the data locally on the device itself instead of sending it offsite. This can be done in two ways: either by using an embedded system (like an IoT sensor) or by using a gateway device (like Amazon Web Services Lambda).
Edge computing has been used in smart cities for years now–for example, New York City uses sensors at traffic lights to detect when there are too many cars waiting at intersections and adjust timing accordingly so that traffic flows more smoothly as cars move through intersections without stopping too often or idling too long before moving again.
Edge computing doesn’t require fast, expensive internet connections.
Edge computing doesn’t require fast, expensive internet connections. In fact, it actually makes use of slower connections that are less likely to be affected by congestion or interference. This is because edge computing is about processing data closer to where it is generated. It can help solve problems in real time and improve response times for applications running on the cloud or elsewhere.
Edge computing isn’t always the best solution for every problem; cloud computing still has its advantages when it comes to scalability and cost savings (as long as there’s good connectivity). But if you’re looking for solutions that solve specific issues with speed and efficiency, then edge computing might be just what you need!
Edge computing makes data more accessible.
Edge computing is a way to process data closer to the source. This makes it easier for people who are in remote areas or have limited access to resources, such as internet and computer hardware, to access information quickly and efficiently.
It also means that data can be processed and analyzed faster because there’s less distance between the device collecting it and where you want that information processed.
Edge computing can help solve problems in real time.
Edge computing is a new way to process and analyze data. It doesn’t require fast, expensive internet connections, making it ideal for places where there are lack of resources or infrastructure.
Data accessibility is one of the biggest benefits of edge computing because it makes data more accessible to people who need it most–people who live in rural areas or developing countries where there isn’t always access to high-speed internet connections. This means that those who need help can get it faster than ever before!
If you’re interested in learning more about how edge computing can benefit your business, give us a call today! We’ll be happy to answer any questions you may have about this exciting new technology!
The future of edge computing is bright.
Edge computing is the future of data processing, and it’s here to stay. It is the next big thing in data processing, and it will be used by everyone.
Edge computing is more efficient than traditional approaches because it allows you to process your information closer to where it was generated–in other words, on or near your device instead of at some far-off server farm somewhere. This can make things faster as well as more secure since there are fewer steps between when a user creates something like an email or posts something on social media and when that content reaches its intended audience (or any audience at all).
Finally, edge computing offers cost savings through reduced infrastructure needs: You don’t need servers dedicated solely for storing all this information before sending it back out again; instead you can use existing machines with extra storage space available for such tasks (and even those machines could eventually get smaller as technology advances).
The future of data processing is at the edge of the network, not in the cloud
The future of data processing is at the edge of the network, not in the cloud.
The cloud isn’t always the best solution for processing large amounts of data. For example:
- The cloud isn’t always reliable. If you’re running an application that requires high availability, it may not work well if it relies on a third party service such as AWS or Azure to host your application code and/or data. You could also experience outages due to weather conditions (e.g., hurricanes).
- The cloud can be slow because networks aren’t designed for real-time response times from across continents; this is especially true when dealing with IoT devices that often have limited bandwidth capabilities compared to desktop PCs or laptops which have faster connections available through WiFi routers at home or office locations
Conclusion
So, what does the future look like? Edge computing is still in its early days, but we can already see how it will transform our world. With faster connections and more data centers at the edge of the network, we’ll be able to access information anywhere there’s internet access–even on our phones! There are also exciting possibilities for businesses who want their data processed faster or analyzed on-site rather than waiting for an answer from Google or Amazon Web Services (AWS).
